
It’s no secret. We are officially living in the era of big data. Almost every company, and notably the larger ones, collects, stores, and analyzes data for the purpose of expansion. Databases, automation systems, and customer relationship management (CRM) platforms are commonplace in the day-to-day operations of most businesses. If you have worked in any organization for any time, then you’ve probably heard of the term data normalization. Data normalization is an organization-wide success booster since it is a best practice for managing and utilizing data stores. In this article, we will discuss data normalization software, data mining, and Python.
What Is Data Normalization?
Data normalization is a procedure that “cleans” the data so that it can be entered more consistently. If you want to save your data in the most efficient and effective way possible, you should normalize it by getting rid of any redundant or unstructured information.
Furthermore, data normalization’s primary objective is to make all of your system’s data conform to the same format. Better business decisions can be made with the data now that it is easier to query and evaluate.
Your data pipeline could benefit from data normalization, which promotes data observability (the ability to see and understand your data). In the end, normalizing your data is a step in the direction of optimizing your data or getting the most value out of it.
How Data Normalization Works
It’s worth noting now that normalization will take on a variety of appearances depending on the data type.
Normalization, at its core, entails nothing more than ensuring that all data within an organization follows the same structure.
- Miss EMILY will be written in Ms. Emily
- 8023097864 will be written 802-309-7864
- 24 Canillas RD will be written 24 Canillas Road
- GoogleBiz will be written by Google Biz, Inc.
- VP marketing will be written Vice President of Marketing
Experts agree that, beyond simple formatting, there are five guidelines or “normal forms,” that must be followed when normalizing data. Entity types are sorted into numeric categories based on their level of complexity in accordance with each rule. While norms are generally accepted as recommendations for standardization, there are circumstances where departures from the norm are necessary. Consequences and outliers need to be taken into account while dealing with variations.
What Are the 5 Rules of Data Normalization?
As a rule of thumb, “normal forms” can be used to guide a data scientist through the process of normalization. These data normalization rules are organized into tiers, with each rule building on the one before it. This means that before moving on to the next set of rules, you must ensure that your data satisfies the requirements of the previous set of rules.
There are many different normal forms that can be used for data normalization, but here are five of the most popular and widely used normal forms that work with the vast majority of data sets.
#1. First Normal Form (1NF)
The other normal forms build upon the first normal form as the starting point of normalization. It’s the primary key, and it includes paring down your attributes, relations, columns, and tables. To do this, one must first start by deleting any duplicate data throughout the database. Among the steps required to get rid of duplicates and meet the 1NF are:
- There is a primary key: no duplicate n values within a list or sequence.
- No repeating groups.
- Atomic columns: cells have a single value and each record is unique.
#2. Second Normal Form (2NF)
This is the most strict form of normalization, and it requires that every column in a table be a function of some other column in the table if it does not directly determine the contents of some other column. For instance, in a data table comprising the customer ID, the product sold, and the price of the product at the time of sale, the pricing would be a function of both the customer ID (entitled to a discount) and the specific product. That third column’s information is reliant on what’s in the first two columns and is called a “dependent column.” This dependency does not occur in the 1NF scenario.
Additionally, the customer ID column is a primary key because it uniquely identifies each row in the corresponding table and meets the other requirements for such a role as laid out by best practices in database administration. Both its values and its lack of support for NULL entries remain constant over time.
The other column names above are also potential keys in the aforementioned scenario. In addition, the properties of those candidate keys that make them unique are called prime attributes.
#3. Third Normal Form (3NF)
Modifications are still feasible at the second normal form level since updating one row in a database can have unintended consequences for data that references this information from another table. To illustrate, if we delete a row from the customer table that details a customer’s purchase (due to a return, for instance), we also delete the information that the product has a specific price. To keep track of product pricing independently, the third normal form would split these tables in half.
The Boyce-Codd normal form (BCNF) improves and strengthens the methods used in the 3NF to handle certain kinds of errors, and the domain/key normalized form uses keys to make sure that each row in a table is uniquely identified.
Database normalization’s capacity to minimize or eliminate data abnormalities, data redundancies, and data duplications while increasing data integrity has made it a significant part of the data developer’s arsenal for many years. The relational data model is notable for this feature.
#4. Boyce and Codd Normal Form (3.5NF)
The Boyce Codd Normal Form (BCNF) is an extension of the third normal form (3NF) data model. It is also known by its notational notation, 3.5NF. A 3.5NF table is a 3NF table where no candidate keys overlap. These guidelines are part of this typical form:
- It should be in 3NF.
- When X depends on Y functionally, X must be a super key.
To put it another way, if attribute B is prime, then attribute X cannot be a non-prime attribute for the dependency X Y.
#5. Fourth and Fifth Normal Forms (4NF and 5NF)
The 4th and 5th Normal Forms (4NF and 5NF) are higher-level normalization forms that address intricate dependencies, including multivalued dependencies and join dependencies. However, the aforementioned forms are less frequently utilized in comparison to the preceding three, and they are designed to cater to particular scenarios wherein the data exhibits complex interrelationships and dependencies.
Who Needs Data Normalization?
If you want your firm to succeed and expand, you need to normalize your data on a regular basis. One of the most crucial steps in simplifying and speeding up information analysis is doing this. Such problems often slip up when modifying, adding, or removing system information. When human error in data entry is reduced, businesses are left with a fully functional system full of useful information.
With normalization, a company may make better use of its data and invest more heavily and efficiently in data collection. Cross-examining data to find ways to better manage a business becomes a simpler task. Data normalization is a valuable procedure that saves time, space, and money for individuals who regularly aggregate and query data from software-as-a-service applications and for those who acquire data from many sources, including social media, digital sites, and more.
Why Is Normalization Important?
Data normalization is essential for maintaining the integrity, efficiency, and accuracy of databases. It addresses issues related to data redundancy by organizing information into well-structured tables, reducing the risk of inconsistencies that can arise when data is duplicated across multiple entries. This, in turn, promotes a reliable and coherent representation of real-world information.
Normalization also plays a crucial role in improving data integrity. By adhering to normalization rules, updates, insertions, and deletions are less likely to cause anomalies, ensuring that the database accurately reflects changes and maintains consistency over time.
Efficient data retrieval is another key benefit of normalization. Well-organized tables and defined relationships simplify the process of querying databases, leading to faster and more effective data retrieval. This is particularly important in scenarios where quick access to information is critical for decision-making.
Moreover, in analytical processes and machine learning, normalization ensures fair contributions from all attributes, preventing variables with larger scales from dominating the analysis. This promotes accurate insights and enhances the performance of algorithms that rely on consistent attribute scales. In summary, data normalization is fundamental for creating and maintaining high-quality, reliable databases that support effective data management and analysis.
What Are the Goals of Data Normalization?
Although improved analysis leading to expansion is the primary goal of data normalization, the process has several other remarkable advantages, as will be shown below.
#1. Extra Space
When dealing with large, data-heavy databases, the deletion of redundant entries can free up valuable gigabytes and terabytes of storage space. When processing power is reduced due to an excess of superfluous data, the system is said to be “bloated.” After cleansing digital memory, your systems will function faster and load quicker, meaning data analysis is done at a more efficient rate.
#2. Mitigating the Effects of Data Irregularities
Data normalization also has the additional benefit of doing away with data outliers, or discrepancies in data storage. Mistakes made while adding, updating, or erasing data from a database indicate flaws in its structure. By adhering to data normalization guidelines, you may rest assured that no data will be entered twice or updated incorrectly and that removing data won’t have any impact on other data sets.
#3. Cost Reduction
When costs are reduced as a result of standardization, all of these advantages add up. For instance, if file sizes are decreased, it will be possible to use smaller data storage and processing units. In addition, improved efficiency from standardization and order will ensure that all workers can get to the database data as rapidly as possible, freeing up more time for other duties.
#4. The Sales Procedure Is Being Streamlined
You can place your company in the best possible position for growth through data normalization. Methods such as lead segmentation help achieve this. Data normal forms guarantee that groupings of contacts can be broken down into granular classifications according to factors like job function, industry, geographic region, and more. All of this makes it less of a hassle for commercial growth teams to track down details about a prospect.
#5. Reduces Redundancy
The issue of redundancy in data storage is often disregarded. The reduction of redundancy will ultimately lead to a decrease in file size, resulting in improved efficiency in analysis and data processing.
Challenges of Data Normalization
Although data normalization has many benefits for businesses, there are also certain downsides that should be considered:
#1. Query Response Times That Are Slower
Some analytical queries, especially those that require pulling through a large quantity of data, may take your database longer to execute when using a more advanced level of normalization. Scanning databases takes more time because of the need to employ numerous data tables to comply with normalized data requirements. The cost of storage is expected to drop over time, but for the time being, the trade-off is faster query times at the expense of less space.
#2. Increased Difficulty for Groups
In addition to establishing the database, training the appropriate personnel to use it is essential. Data that conforms to conventional forms is typically stored as numbers; hence, many tables just include codes rather than actual data. This implies the query table should be used in every query.
#3. Denormalization as an Alternative
Developers and data architects continue to create document-centric NoSQL databases and non-relational systems that don’t require disk storage. A balance between data normalization and denormalization is being progressively considered.
#4. Accurate Knowledge Is Necessary
You can’t standardize your data without first having a solid understanding of the underlying data’s typical forms and structures. Significant data anomalies will be experienced if the initial process is flawed.
Data Normalization in Data Mining
In data mining, data normalization plays a crucial role in enhancing the quality and effectiveness of analytical processes. The primary goal is to transform raw data into a standardized format that facilitates meaningful pattern recognition, model development, and decision-making. Normalization is especially pertinent when dealing with diverse datasets containing variables with different scales, units, or measurement ranges.
By normalizing data in data mining, one ensures that each attribute contributes proportionately to the analysis, preventing certain features from dominating due to their inherent scale. This is particularly important in algorithms that rely on distance measures, such as k-nearest neighbors or clustering algorithms, where variations in scale could distort results. Normalization aids in achieving a level playing field for all attributes, promoting fair and accurate comparisons during the mining process.
Moreover, normalization supports the efficiency of machine learning algorithms by expediting convergence during training. Algorithms like gradient descent converge faster when dealing with normalized data, as the optimization process becomes less sensitive to varying scales.
In conclusion, data normalization is an important step in the preprocessing stage of data mining. It makes sure that all data attributes are treated equally in analyses, stops biases caused by differences in size, and makes algorithms more efficient and accurate at finding meaningful patterns in large datasets.
How to Normalize Data
Now that you know why it’s important for your company and what it entails, you can start training for it. A general procedure for normalizing data, including factors to think about while choosing a tool, is as follows:
#1. Identify the Need for Normalization
Data normalization is necessary whenever there are problems with misunderstandings, imprecise reports, or inconsistent data representation.
#2. Select Appropriate Tools
Check for built-in data normalization features before committing to a solution. For instance, InvGate Insight not only helps but also completes the task for you. In other words, it streamlines your processes by automatically standardizing all the data in your IT inventory.
#3. Understand the Data Normalization Process
Normalization guidelines or forms are often used in this process. These guidelines are fundamental to the method, and we’ll examine them in further depth in the next sections. They direct the process of reorganizing data in order to get rid of duplicates, make sure everything is consistent, and set up links between tables.
#4. Examine and Evaluate Connections in the Data
The time to begin is after the foundation has been laid. Determine the main keys, dependencies, and properties of the data entities by analyzing their connections with one another. In the normalization process, this helps spot any duplications or outliers that need fixing.
#5. Normalization Norms Should Be Used
In order to normalize your data, you should use the appropriate rules or forms established by your dataset’s specifications. Common practices for doing so include dividing tables, establishing key-based associations between them, and reserving a single location for storing each piece of data.
#6. Check and Improve
Check the data for correctness, consistency, and completeness. In the event that any problems or outliers were uncovered as a result of normalizing, make the appropriate corrections.
#7. Data Normalization Should Be Documented
Be sure to keep detailed records of your database’s structure, including its tables, keys, and dependencies. This is useful for planning upkeep and improvements to the structure.
What Are Some Commonly Used Data Normalization Techniques?
The normalization of data is an essential part of any data analysis process. It’s the foundation upon which analysts build compilations and comparisons of numbers of varying sizes from diverse datasets. Normalization, however, is not widely known or employed.
Misunderstanding of what normalization actually is likely contributes to its lack of recognition. Normalization can be performed in a variety of ways, from simple ones like rounding to more complex ones like z-score normalization. Here are the most commonly used data normalization techniques:
#1. Decimal Place Normalization
Data tables containing numerical data types undergo decimal-place normalization. Anyone who has dabbled with Excel will recognize this behavior. By default, Excel displays standard comma-separated numbers with two digits after the decimal. You have to pick how many decimals you want and scale this throughout the table.
#2. Data Type Normalization
Another common sort of normalization is data types, and more specifically, numerical data subtypes. When you create a data table in Excel or a SQL-queried database, you may find yourself staring at numerical data that is sometimes recognized as a currency, sometimes as an accounting number, sometimes as text, sometimes as general, sometimes as a number, and sometimes as comma-style. The following are examples of data types for numbers:
- Currency
- Accounting number
- Text
- General
- Number
- Comma-style
The problem is that these subtypes of numerical data respond differently to formulas and various analytical procedures. In other words, you’ll want to be sure they’re of the same type.
In my opinion, comma-style references are the most reliable. It’s the clearest, and it can be labeled as a monetary amount or an accounting figure if necessary for a later presentation. Excel also receives the fewest updates over time, making it future-proof in terms of both software and operating systems.
#3. Z-Score Normalization
We’ve discussed data discrepancies, but what about when you have numbers with widely varying sizes across various dimensions?
It’s not easy to compare the relative changes of two dimensions if one has values from 10 to 100 and the other has values from 100 to 100,000. When this problem arises, normalization is the answer.
Z-scores are among the most prevalent techniques for normalization. Each data point is normalized to the standard deviation with the use of a z-score. Here is the equation:
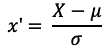
where X is the data value, μ is the mean of the dataset, and σ is the standard deviation.
#4. Clipping Normalization
Although it is not a normalization technique in and of itself, analysts use clipping either before or after using normalization techniques. In short, clipping consists of establishing maximum and minimum values for the dataset and requalifying outliers to these new max or mins.
Take the set of numbers [14, 12, 19, 11, 15, 17, 18, 95] as an example. The value of 95 stands well outside the rest of the distribution. We can remove it from the records by setting a new peak. If you remove 95 from your range, you have 11–19; therefore, you might give it the number 19.
Clipping does not eliminate data points; rather, it reorganizes the points already present in the dataset. To double-check your work, compare the pre-and post-clipped versions of the data population N and ensure that there are no outliers.
Data Normalization Python
In Python, data normalization can be efficiently performed using various libraries, with sci-kit-learn being a popular choice. The MinMaxScaler and StandardScaler classes in sci-kit-learn provide easy-to-use methods for Min-Max scaling and Z-score normalization, respectively.
Here’s a brief example using Min-Max scaling:
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# Sample data
data = np.array([[1.0, 2.0],
[2.0, 3.0],
[3.0, 4.0]])
# Create MinMaxScaler
scaler = MinMaxScaler()
# Fit and transform the data
normalized_data = scaler.fit_transform(data)
print(“Original Data:\n”, data)
print(“\nNormalized Data:\n”, normalized_data)
For Z-score normalization:
from sklearn.preprocessing import StandardScaler
# Create StandardScaler
scaler = StandardScaler()
# Fit and transform the data
standardized_data = scaler.fit_transform(data)
print(“Original Data:\n”, data)
print(“\nStandardized Data:\n”, standardized_data)
These libraries simplify the normalization process, making it accessible for various datasets and applications in Python-based data analysis and machine learning workflows.
Data Normalization Software
There are several software tools available for data normalization, each catering to different needs and preferences. One widely used tool is OpenRefine, an open-source platform that facilitates data cleaning, transformation, and normalization. OpenRefine provides a user-friendly interface for exploring, cleaning, and transforming diverse datasets, making it particularly useful for preprocessing tasks.
Another popular choice is RapidMiner, an integrated data science platform that offers a range of tools, including data preprocessing and normalization. RapidMiner provides a visual environment for designing data workflows, making it accessible for users with varying levels of technical expertise.
Knime Analytics Platform is an open-source data analytics, reporting, and integration platform that supports data preprocessing tasks, including normalization. It allows users to create visual data workflows using a modular and flexible architecture.
For those working with large-scale data, Apache Spark is a powerful open-source distributed computing system that includes MLlib, a machine learning library. Spark provides functionalities for data preprocessing and transformation, including normalization, at scale.
Additionally, programming languages like Python with libraries such as scikit-learn and pandas offer extensive capabilities for data normalization. Python’s flexibility and rich ecosystem make it a popular choice among data scientists and analysts for implementing custom normalization processes.
The choice of software depends on factors like the specific requirements of the task, the scale of the data, and the user’s familiarity with the tool’s interface and programming languages.
What Will Happen if You Don’t Normalize Your Data?
If you don’t normalize your data, it can lead to several issues in data analysis and machine learning. One significant problem is that features with different scales can disproportionately influence models. Algorithms sensitive to the magnitude of variables, like k-nearest neighbors or support vector machines, might give more weight to larger-scale features, impacting the model’s accuracy. Additionally, normalization helps in dealing with outliers and ensures fair comparisons between variables during analysis. Without normalization, trends and patterns might be obscured, and the performance of machine learning models could be suboptimal. Inconsistent scales also make it challenging to interpret the relative importance of different features, hindering the understanding of the data and potentially leading to incorrect conclusions.
Bottom Line
Despite the fact that normalizing data is a time-consuming procedure, the benefits are well worth the investment. The data you collect from several sources will be largely meaningless and useless unless you normalize it.
While databases and systems may change to enable less storage, it’s still necessary to adopt a uniform format for your data to eliminate any data duplication, anomalies, or redundancies to improve the overall integrity of your data. Data normalization unleashes economic potential, boosting the functionality and growth possibilities of every organization. For this reason, normalizing your company’s data is a must-do right now.
Frequently Asked Questions
What is normalization in SQL?
Normalization in SQL is a process that removes data redundancy and improves data integrity. It also helps to organize data in a database.
Why do we need Normalisation in SQL?
Data normalization is crucial because it eliminates redundant information and ensures that only relevant data is stored in a database. Because of this, normalization guarantees that the database has more available space.
Similar Articles
- SCALE COMPUTING: Profile, Features, Reviews & Alternatives 2023
- How to Remove Table in Excel: Easy Methods
- HOW TO CREATE A RULE IN OUTLOOK: EASY Guide
- TOP BEST PDF EDITOR FOR MAC IN 2023 (Free, Paid, Online)





